前言
此篇博文是笔者所总结的 Docker 系列之一;
本文为作者的原创作品,转载需注明出处;本文采用是 Docker Engine 1.12;
Nodes 架构
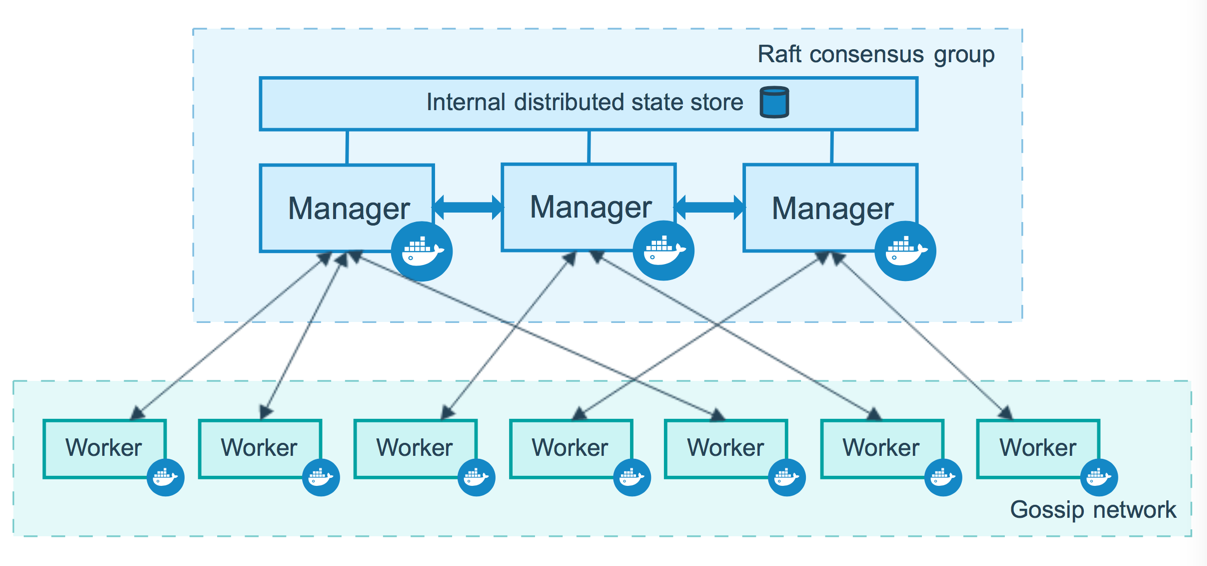
如图,可以看到,Swarm 集群是由 Manager 和 Worker 两种类型的节点所构成;
Manager nodes
Manger 节点,顾名思义,是进行 Swarm 集群的管理工作的,它的管理工作集中在如下部分,
- 维护一个集群的状态;
- 对 Services 进行调度;
- 为 Swarm 提供外部可调用的 API 接口;
Manager 节点需要时刻维护和保存当前 Swarm 集群中各个节点的一致性状态,这里主要是指各个 Tasks 的执行的状态和其它节点的状态;因为 Swarm 集群是一个典型的分布式集群,在保证一致性上,Manager 节点采用 Raft 协议来保证分布式场景下的数据一致性;
通常为了保证 Manager 节点的高可用,Docker 建议你采用奇数个 Manager 节点,这样的话,你可以在 Manager 失败的时候不用关机维护,我们给出如下的建议,
- 3 个 Manager 节点最多可以同时容忍 1 个 Manager 节点失效的情况下保证高可用;
- 5 个 Manager 节点最多可以同时容忍 2 个 Manager 节点失效的情况下保证高可用;
- $N$ 个 Manager 节点最多可以同时容忍 $(N-1)\over 2$ 个 Manager 节点失效的情况下保证高可用;
- Docker 建议最多最多的情况下,使用 7 个 Manager 节点就够了,否则反而会降低集群的性能了;
Worker nodes
Worker 节点和 Manager 节点一样,同样都是运行在宿主机上的 Docker Engine,只是 Worker 节点的目的更为简单,它就是用来执行 Task 的;而默认情况下 Manager 节点也同样是 Worker 节点,同样可以执行 Task;其它更多有关 Worker nodes 的相关操作,参看笔者的实战篇;
更换角色
你可以手动的通过输入 docker node promote 命令将一个 Worker 节点提升为 Manager 节点,通常情况下,该命令使用在维护的过程中,需要将 Manager 节点占时下线进行维护操作;同样可以使用 docker node demote 将某个 manager 节点降级为 worker 节点。
Services 架构
在微服务部署的过程中,通常将某一个微服务封装为 Service 在 Swarm 中部署执行,通常你需要通过指定容器 image 以及需要在容器中执行的 Commands 来创建你的 Service,除此之外,通常,还需要配置如下选项,
- 指定可以在 Swarm 之外可以被访问的服务端口号 port,
- 指定加入某个 Overlay 网络以便 Service 与 Service 之间可以建立连接并通讯,
- 指定该 Service 所要使用的 CPU 和 内存的大小,
- 指定一个滚动更新的策略 (Rolling Update Policy)
- 指定多少个 Task 的副本 (replicas) 在 Swarm 集群中同时存在,
Services,Tasks 和 Containers 之间的关系
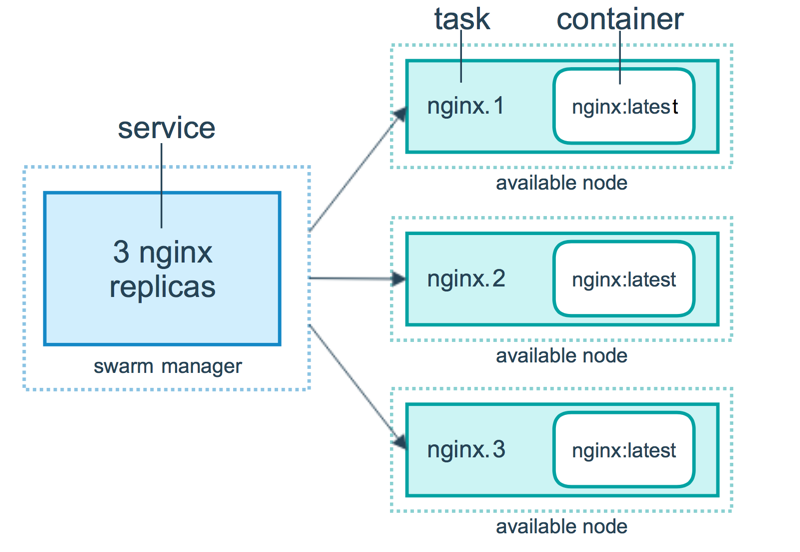
三者之间的关系可以用上面这张图来描述;来看这张图的逻辑,表示用户想要通过 Manager 节点部署一个有 3 个副本的 Nginx 的 Service,Manager 节点接收到用户的 Service definition 后,便开始对该 Service 进行调度,将会在当前可用的节点中启动相应的 Tasks 以及相关的副本;所以可以看到,Service 实际上是 Task 的定义,而 Task 则是执行在节点上的程序;
Task 是什么呢?其实就是一个 Container,只是,在 Swarm 中,每个 Task 都有自己的名字和编号,如图,比如 nginx.1、nginx.2 和 nginx.3,这些 Container 各自运行在各自的 node 上,当然,一个 node 上可以运行多个 Container;
Task 的调度
调度过程
The underlying logic of Docker swarm mode is a general purpose scheduler and orchestrator.
Docker swarm mode 模式的底层技术实际上就是指的是调度器( scheduler )和编排器( orchestrator );下面这张图展示了 Swarm mode 如何从一个 Service 的创建请求并且成功将该 Service 分发到两个 worker 节点上执行的过程,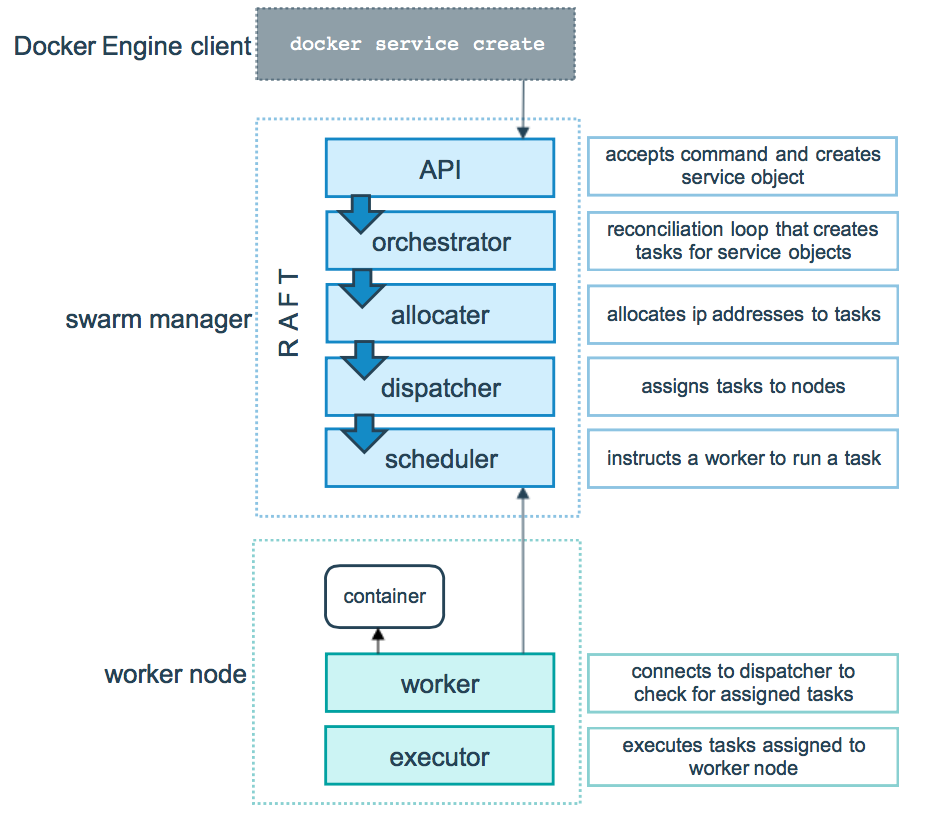
首先,看上半场,Swarm manager 的部分
- 用户通过 Docker Engine Client 使用命令 docker service create 提交 Service definition,
- 根据 Service definition 创建相应的 Task,
- 为 Task 分配 IP 地址,
注意,这是分配运行在 Swarm 集群中 Container 的 IP 地址,该 IP 地址最佳的分配地点是在这里,因为 Manager 节点上保存得有最新最全的 Tasks 的状态信息,为了保证不与其他的 Task 分配到相同的 IP,所以在这里就将 IP 地址给初始化好; - 将 Task 分发到 Node 上,可以是 Manager 节点也可以使 Worker 节点,
- 对 Worker 节点进行相应的初始化使得它可以执行 Task
下半场,Work 节点部分
该部分就相对简单许多- 首先连接 manager 的分配器( dispatcher )检查该 task
- 验证通过以后,便开始通过 Worker 节点上的执行期( executor )执行;
注意,上述 task 的执行过程是一种单向机制,比如它会按顺序的依次经历 assigned, prepared 和 running 等执行状态,不过在某些特殊情况下,在执行过程中,某个 task 失败了( fails ),编排器( orchestrator )直接将该 task 以及它的 container 给删除掉,然后在其它节点上另外创建并执行该 task;
待执行状态
如果在某个 service 的调度过程中,发现当前没有可用的 node 资源可以执行该 service,这个时候,该 service 的状态将会保持为 pending 的状态;下面,我们来看一些例子可能使得 service 维持在 pendding 状态,
- 如果当所有的节点都被停止或者进入了 drained 状态,这个时候,你试图创建一个 service,该 service 将会一直保持 pending 状态直到当前某个节点可用为止;不过要注意的是,第一个恢复的 node 将会得到所有的 task 调度请求,接收并执行,因此,这种情况在 production 环境上要尽量避免;
- 你可以为你的 service 设置执行所需的内存大小,在调度的过程当中,发现没有一个 node 能够满足你的内存请求,那么你当前的 service 将会一直处于 pending 状态直到有满足需求的 node 出现;
上面的例子都表明一个事实,就是你期望的执行条件与 Swarm 现有的可用资源的情况不匹配,不吻合,因此,作为 Swarm 的管理者,应该考虑对 Swarm 集群整体进行扩容;
Replicated 和 Global Services
有两种方式可以对 service 进行部署,一种是 Replicated 模式,一种是 Global 模式;下面这张图展示了两者之间的异同,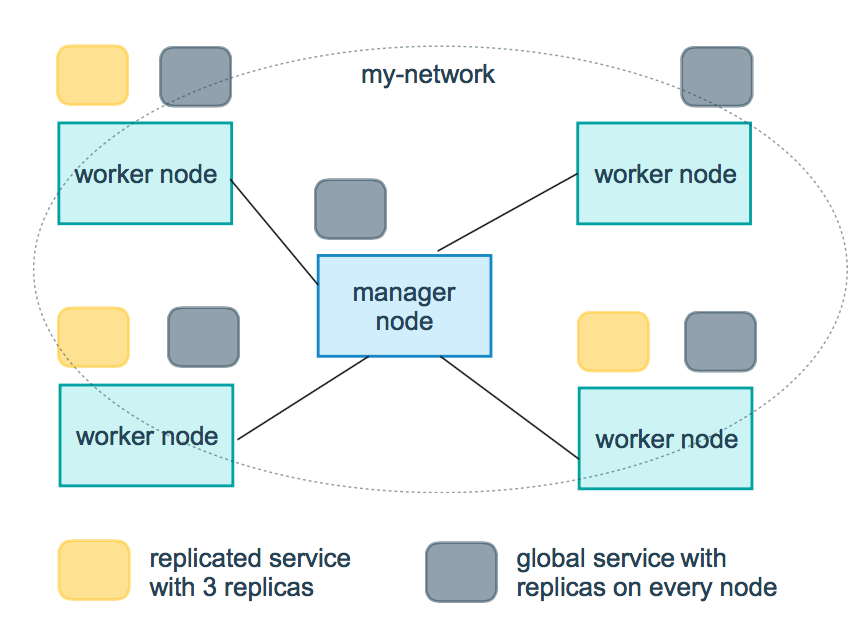
- Replicated 模式
通过用户指定需要在集群中执行多少个副本,如图,黄色小方块表示正在集群中执行的 3 个 replica Tasks; - Global 模式
如图,灰色小方块表示每个节点上都分别执行了一个该 replica Task;
Docker 公钥基础设置 PKI
The swarm mode public key infrastructure (PKI) system built into Docker makes it simple to securely deploy a container orchestration system.
more refer to https://docs.docker.com/engine/swarm/how-swarm-mode-works/pki/
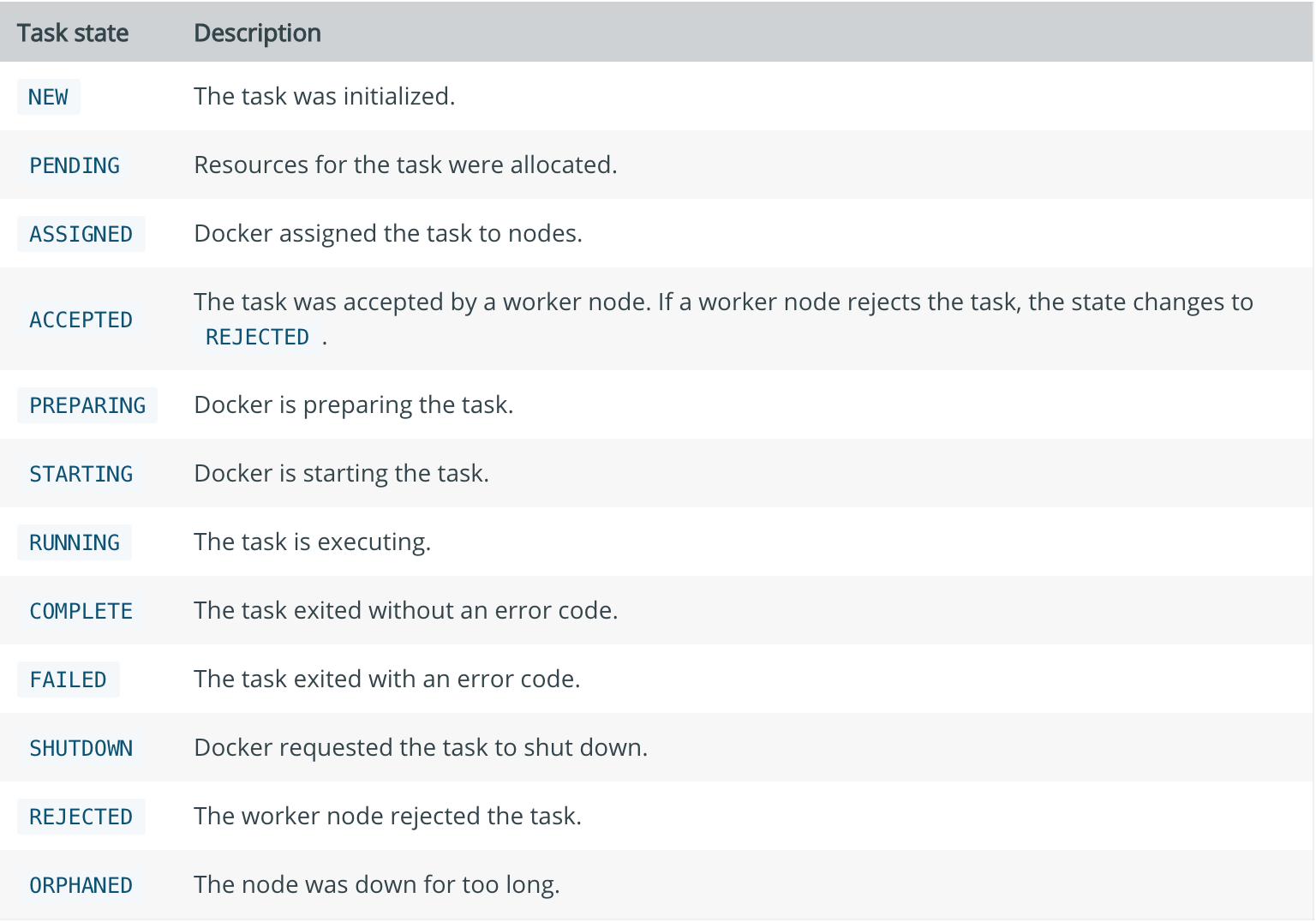
Task states
所有状态
查看某个任务的状态
1 | $ docker service ps webserver |
Swarm 调度器的调度策略
TODO
Swarm在schedule节点运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random.
Random顾名思义,就是随机选择一个Node来运行容器,一般用作调试用,spread和binpack策略会根据各个节点的可用的CPU, RAM以及正在运行的容器的数量来计算应该运行容器的节点。
在同等条件下,Spread策略会选择运行容器最少的那台节点来运行新的容器,binpack策略会选择运行容器最集中的那台机器来运行新的节点(The binpack strategy causes Swarm to optimize for the container which is most packed.)。
使用Spread策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。
Binpack策略最大化的避免容器碎片化,就是说binpack策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在一个节点上面。
References
https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/